It was June 2016, and we were into the last phase of planning for the changes we needed to make for our upcoming 45 day sale period which started in July, and where we were expecting a steep surge in traffic.
Since our first product launch last October, we were using AWS’ services in North Virginia, due to cheaper costs and wider availability of the services that were being offered. Over a period of time, we saw the high latency for the connections coming from the majority of our traffic in India.
Initially, we thought of moving our infrastructure to Singapore, and including the use of Akamai’s hop reduction solution from a client ISP to the data centre in the cloud. But 24-hours prior to the actual migration, we got a confirmation of the launch of AWS Mumbai data centres. So we got our new infrastructure placed in the Mumbai data centres.
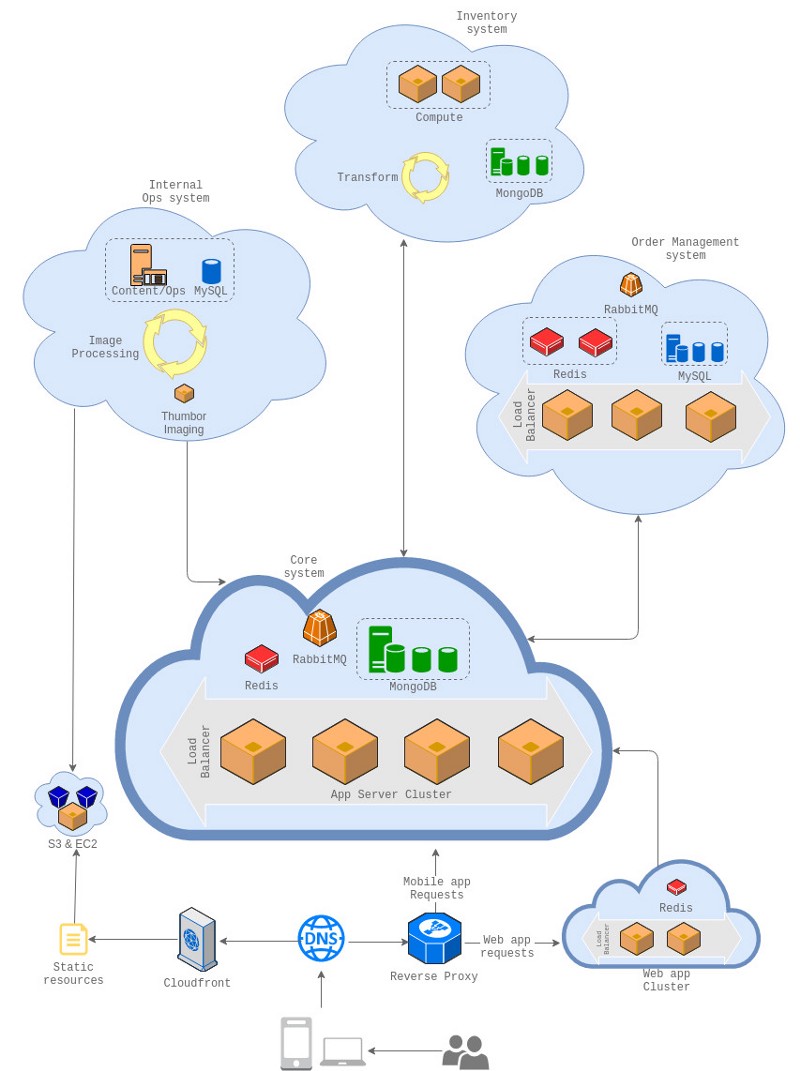
Fynd’s New Infrastructure
There are separate sub-systems and projects which, once unified gives us the final Fynd product we see as the mobile app and the web app. The product itself is designed as micro-services architecture, and each of these services are maintained and developed using the best fit tools for us. Django, Tornado, Node.js, and Spring being the core for some of these systems.
Optimisations
1. Identified the popular and slow APIs and improved them:
Any API that takes over 50 minutes to process, is a “slow API” for us. We put extra efforts to make sure how it can be taken care of. For some, it might be easier to implement, for some, it might need moderate changes and for some, it before very difficult, especially for the ones where you’re dependent on external services
At the beginning of the sale period we had average response time for our APIs from 40–50 ms, which was reduced by around 40% eventually.
2. Increased availability: All the dynamic requests to our app servers originating from either the mobile apps or the web apps were placed behind load-balancers. The increase in redundancy in the database cluster by adding more read-replicas.



3. With the rise in number of active users reduced the number of open data connections required per user: We grouped users into multiple buckets based upon their usage pattern, and for the requests coming from those users we were only using a single connection using a small TTL-based cache.
(For example: So ideally if 20 connections are required by 10 users for in 1 sec, then only 20 connections will still be required for 100 users in that 1 second)
4. Re-using existing TCP socket connection rather than creating a new one: Using a higher keep-alive and ensuring that connection establishment overheads are avoided from the same clients. Using connection pooling for any DB connection or any external socket connection.
5. Pre-compute the obvious and keep results ready: This is even true at the database level. Try to keep your caches warm. It might be better to keep a cache warm and unused, rather than missing the cache.
6. Tune data stores to make most use of the underlying hardware:
Monitor, analyse and check if existing hardwares were being used to their full potential and resource availability. It might mean fine-tuning your Mongo, SOLR or any other data store we’re using.
Scale To Deal With

Nice To Haves
- Move everything static to CDNs, and make sure you have dynamic URL referencing to make use of parallel downloads from your clients.
- The micro-services transfers should be on high speed and low latency private network connections within the same availability zone.
Things To Avoid
- Some of your favourite libraries/tools might be adding more overheads than you realise. Certain sections of code were refactored to use PyMongo directly instead of using MongoEngine document mapper. It leads up to 40% reduction in CPU timings where the documents were nested. Certain Django Rest Framework serialisers were replaced with simple Python serialisers, and it saved around 20–30% CPU utilisation.
- Continuing the SSL to the app servers unless required. Terminate the SSL to your LB.
What We Achieved
- Intra-server latency reduction by around 2x.
- Decrease in the number of data-store connections per user by around 12x.
- 40–50 ms of average response time per request during the start of the sale period, to 20–30 ms average response time in the last 4 days.
- Average server utilisation raised from 4% to 7% during peak periods, even with the rise in orders by 200x.

Finally, as a result, we rose to number four on the App and Play stores, in the shopping category on August 16, 2016.
[This post originally appeared on Fynd’s official blog and has been reproduced with permission.]