






Inc42 Daily Brief
Stay Ahead With Daily News & Analysis on India’s Tech & Startup Economy
We use celery extensively for all our tasks queues, and have a logical division of the queues based on the type of work they do. Primarily we divide the queues in two different buckets:
First Level Division
- I/O based task queues (gevent)
- CPU bound task queues (prefork)
Second Level Division
- Fast running tasks
- Slow running task
- High priority tasks
- Low priority tasks
This helps us configure celery for maximum throughput.
Some very important learnings from using celery in the past one year.
- For I/O bound queues use gevent and make sure that your code does not perform any blocking calls or the whole purpose will fail. Refer: What is gevent? — gevent 1.2.0.dev0 documentation
- Gevent increases the throughput of our I/O bound queues considerably.
celery -A proj worker -P gevent -c 100 (example from celery docs)
- Use -Ofair to make sure the tasks are distributed evenly. (it comes with an overhead of coordination but the results are more predictable if tasks takes different amount of time to execute.)
- Use –maxtasksperchild argument to tell celery to use a particular worker for only n number of tasks, if you think there is even a slight possibility of memory leak. Celery can kill a worker and re-spawn a new one to make sure memory is released and it does not hamper the systems performance. ( I am not saying that you should not fix your code :p)
- Use a global timeout to make sure your workers does not get stuck. You can set soft and hard timeout and even notify the task to wrap up or log stuff before it is killed by celery using the soft timeout option.
- Use the retry option carefully, always use exponential back-off so that your systems are not unnecessarily trying to call that third party api which is under maintenance for the next 30mins. Also always define the max number of retries.
- Use connection pool to connect to databases, instead of creating a new connection in the worker every time.
Finally the biggest learning of them all: DNS lookup is time consuming if not configured properly.
We saw constantly that average DNS lookup times on our production machines were around 100ms. We fixed it by installing and configuring Unbound (a local DNS cache) which reduced the subsequent lookup times to less than 1ms.
We also optimized “net.ipv4.ip_conntrack_max” setting in sysctl to make sure we don’t drop packets when there are thousands of tcp calls happening simultaneously.

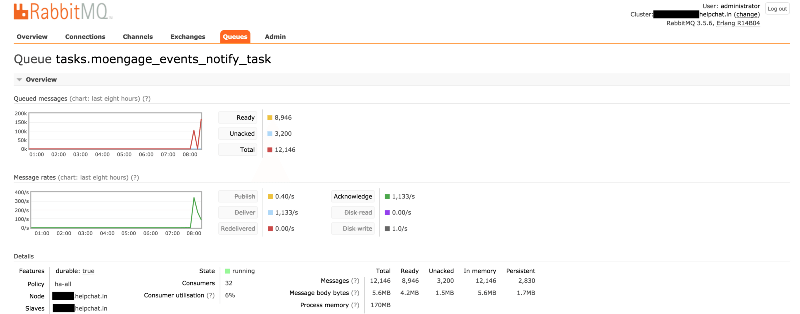
What we did next to achieve even higher throughput (around 8000 tasks per second) is to use NodeJS as our consumer , as NodeJS has awesome async features. (Will write about it in my next post)
If you want to get into more detail, please feel free to ping me.
Cheers!!!
{{#name}}{{name}}{{/name}}{{^name}}-{{/name}}
{{#description}}{{description}}...{{/description}}{{^description}}-{{/description}}
Note: We at Inc42 take our ethics very seriously. More information about it can be found here.