SUMMARY
An Exclusive Inside Look At Embibe's Data Science Lab




[This is the second part of the series How We Are Using Deep Tech And Data Science To Personalize Education]
We built Embibe with a singular vision: to maximise learning outcomes at scale. Making a positive impact to a user’s learning outcome is a difficult, but important, problem to solve. In fact, there are a number of non-trivial open sub-problems, each of which needs to be solved in order to realise the lofty goal of intentionally and positively affecting learning outcomes.
But first, what are learning outcomes? And why do we care about them?
In today’s highly competitive world, a student is measured to a large extent by how much she can score in a competitive exam or even school classroom. Her score can have a significant impact on her career options. For the purposes of this article, let us frame learning outcomes as a function of a student’s innate as well as trainable potential, to learn, absorb, and apply content material optimally, within strictly specified time constraints; so that she can maximise her score in any particular competitive academic context.
In developing countries like India, the student-to-teacher ratio is highly skewed and teachers cannot effectively provide personalised attention at an individual level. This leads to a dilemma, given that each student learns and absorbs information at different rates and has different levels of aptitude. A known side-effect of the inability of teachers to provide personalised attention is that for any given classroom/collection of students, the learning material is always presented to cater to the “average” student. Therefore, very bright students do not reach their full potential and will not be able to truly flex their academic muscle, while scholastically weaker students will have a hard time coping with the rest of the classroom. However, existing online learning platforms and systems are not able to truly facilitate personalised learning at the student level.
Most current systems only account for how well a student can match their solutions to test modules as specified by some administrator of the system. Personalised learning for competitive exams should maximise a student’s score for any academic target in the limited time available to her. Personalised learning should also constructively address the student’s ability gaps not only at the knowledge or aptitude level, but also at the attitudinal and behavioural levels. This lack of effective tools for personalised learning, tailored specifically and precisely for each student, is responsible for her not being able to realise her potential in achieving the maximum possible score in any given exam.
In this article, embibe’s data science team will lay the foundation of the various interconnected data-related problems that need to be addressed in order to maximise learning outcomes, and specifically, score improvement. There are two major dimensions to this problem – Content Ingestion and Content Delivery. Each dimension poses unique challenges in a number of areas that are sure to fascinate any data scientist.
Content Ingestion
Auto ingestion of content
Dozens of syllabus boards, thousands of chapters and concepts, and tens of thousands of institutes and schools result in hundreds of thousands of questions and answers generated and used by instructors every year. Imagine if every student were able to test their knowledge before exams on any subset, or all of these questions, along with getting detailed explanations about the correct answers, and common mistakes made. In order to make this a reality, we are leveraging optical character recognition (OCR) and machine learning to build our own automated ingestion framework that will be highly scalable, truly multilingual, and minimally dependent on human input. And the fun doesn’t stop there. The framework will also be able to ingest handwritten content in a writer-agnostic fashion, thereby rapidly adding to our already fantastic repository of questions, answers, concepts, explanations, and knowledge.
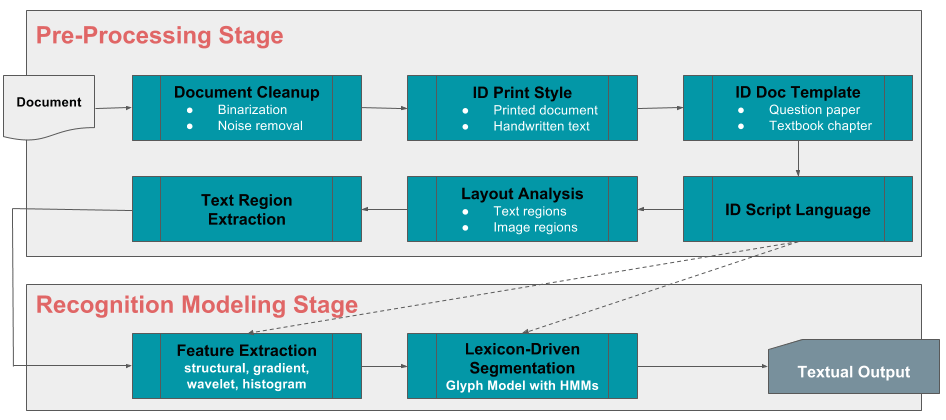
Concept tagging
Alright, so now we have questions, answers, concepts, and chapters all ingested into a massive data warehouse. It would be painful to manually tag each question or chapter with its relevant concepts, or vice versa. Data Science to the rescue! Using bleeding-edge ideas from text classification, topic modelling, and deep learning, we automatically tag concepts to questions, answers, and chapters.

A selection of the most popular concepts as browsed by Embibe users using the Learn feature, in the months of December 2015, January 2016, and February 2016.
Our prior databases containing seed sets of high quality manually tagged content is instrumental as we extract linguistic, lexical, and context-sensitive features, to train state-of-the-art text-tagging models for all the new data that gets ingested into our systems.
Metadata enrichment
There is a wealth of information available online today on any topic that one wishes to learn about. Ideas and concepts build on one another. For instance, the First Law of Thermodynamics is related to the concept of a thermodynamic system, which in turn is related to the concepts of specific heat capacities of gases, conservation of mechanical energy, and work done by a gas, among others. Our content ingestion framework includes data enrichment components that automatically crawl the web and tag content with such diverse pieces of media as text explanations, video links, definitions, user commentary, and forum discussions, all while respecting copyrights, and properly attributing ownership on sourced content. This wealth of available information also makes it possible to automatically connect related concepts in a tree structure. Using ideas from the fields of graph theory, text mining, and label propagation on sparse structures, we create links and interconnections between concepts that share a source→target relationship.
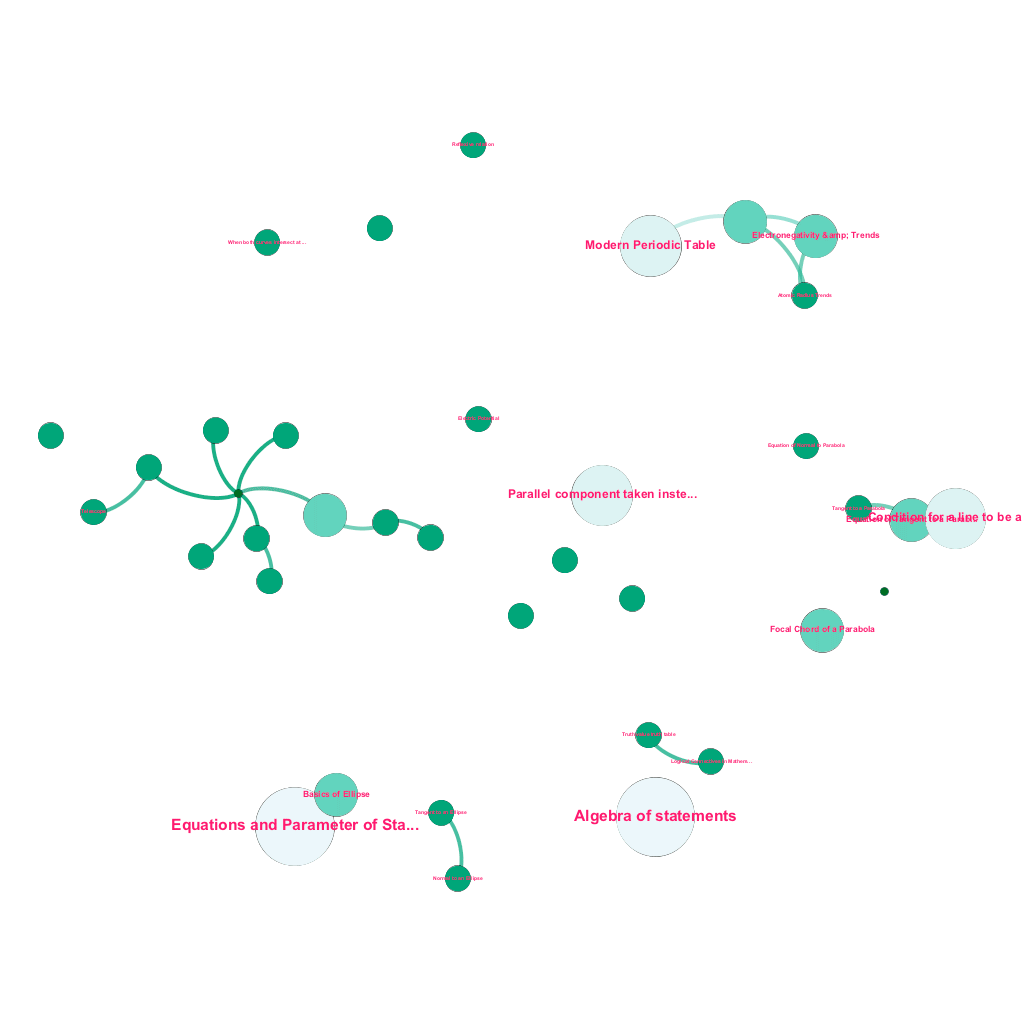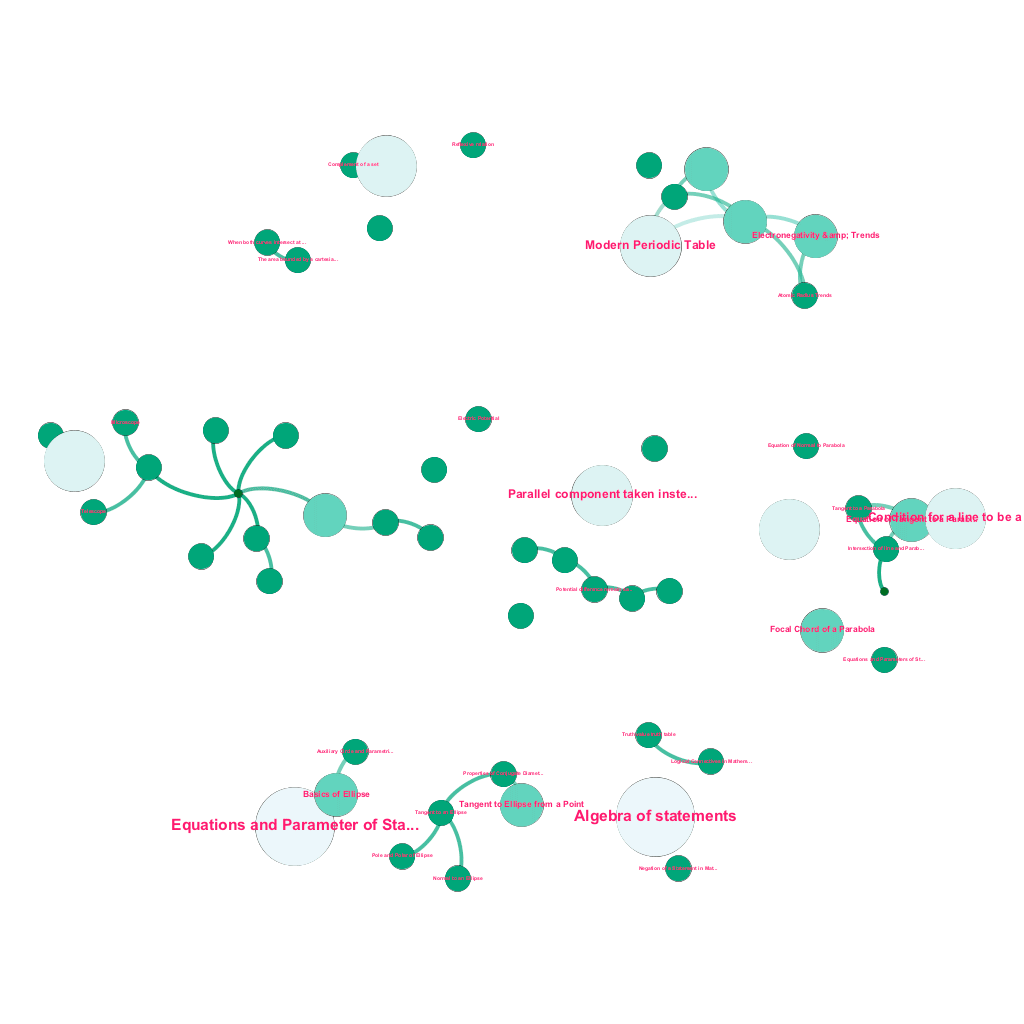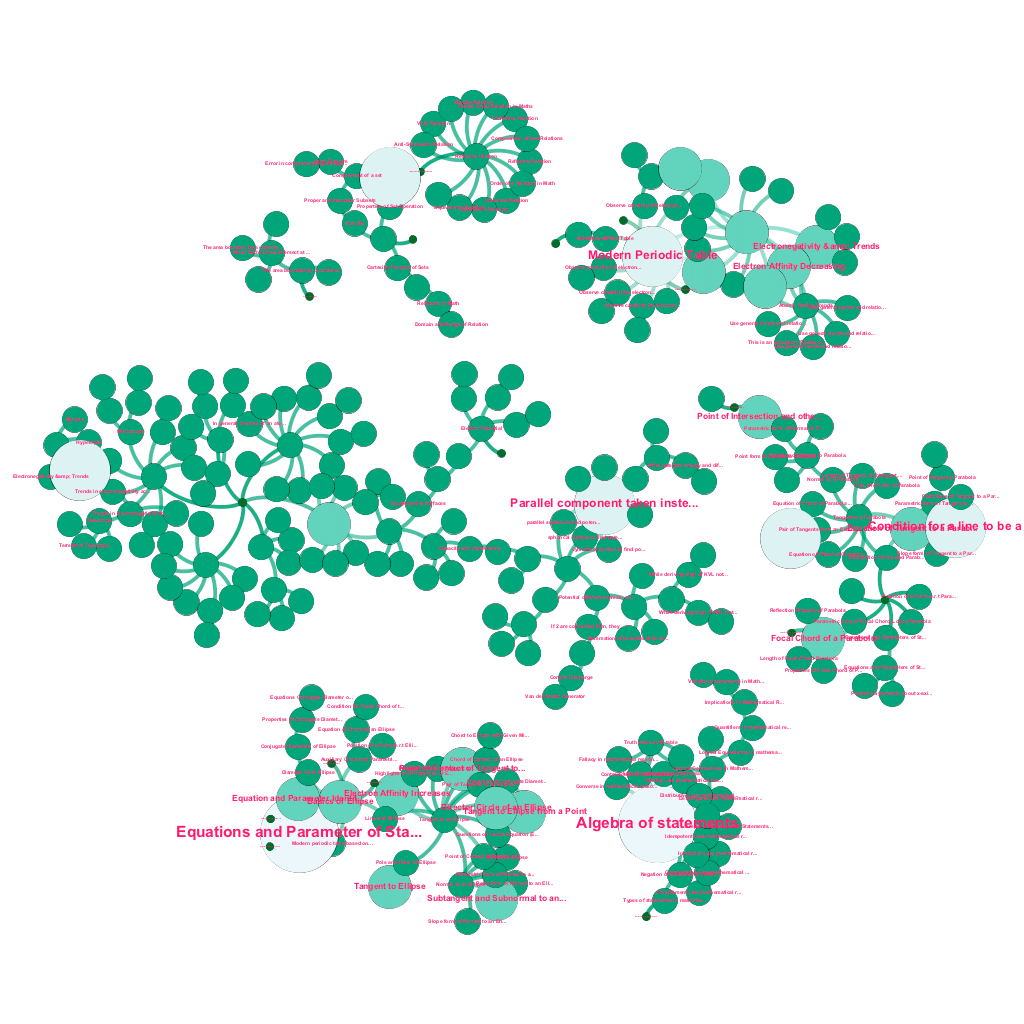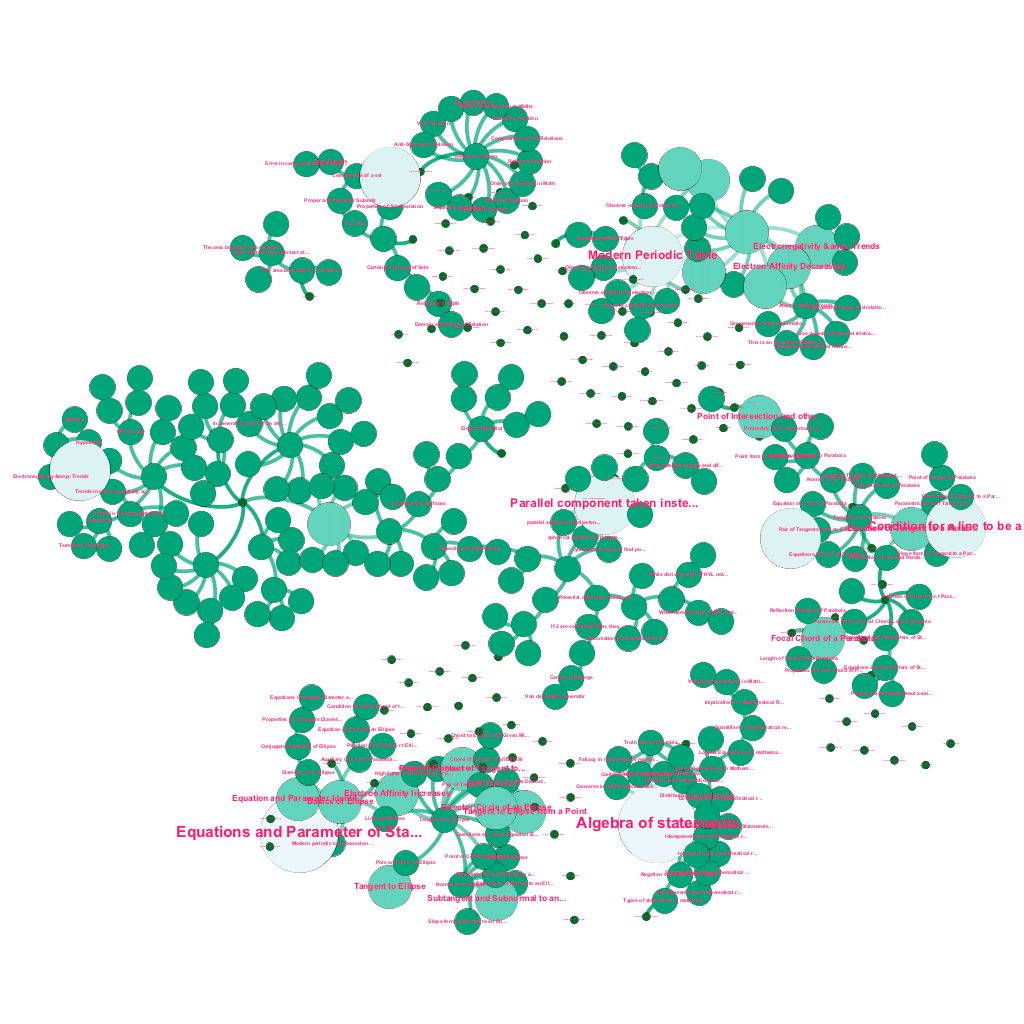
Automated build-out of a tree of concepts, for a subset of ideas from Mathematics, each connected to one or many related concepts
Similar questions clustering
If you were preparing for an exam, would you want to practice the same question over and over again? That would not be helpful. Conversely, imagine how immensely useful it would be to practice a small set of relevant questions that will help you completely master some new concept or chapter. With our access to hundreds of thousands of questions, we have developed the capability to cluster questions based on similarity across a number of dimensions – content-targeted, concept-tested, difficulty level, and exam goals, among others.
Text clustering based on latent semantic information spaces, and their combination with other categorical and numerical feature spaces allow us to precisely group our universe of questions into areas of interest that can be tailored for each individual using Embibe. Additionally, this rich resource of textual data which we have transformed into robust numeric feature spaces related to concept clusters lets us slightly perturb the existing data to generate potentially infinite expressions of the question space. More questions at run time, never seen before! This allows us to give users the maximum value for their time spent on our platform.
Content Delivery
User profiling
We track every move that a user makes on Embibe. The millions of practice and test attempts made by our users over the past three years is calibrated in a data space of many thousands of dimensions. This translates to a space of billions of data points that we can mine to dig deep into our users’ behavioural data and generate insights that correlate with how learning happens. Each additional attempt by a user, tweaks her ability to score higher on the concepts tagged to that attempt, along with the connected preceding and succeeding concepts. This super complex problem involves leveraging ideas from sparse matrix processing, computational algorithms in graph theory, and item response theory to build robust and adaptive user profiles that scale with our growing user base.
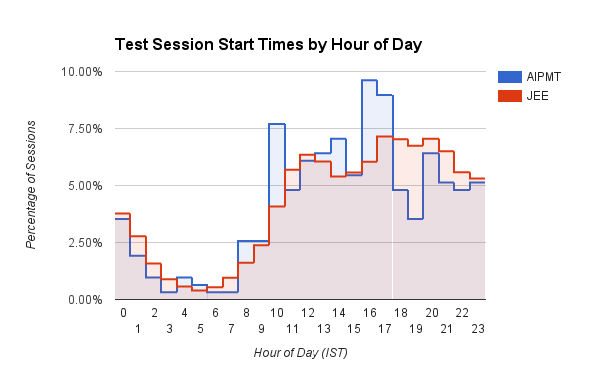



An interesting bar graph that shows the time (hour of day in IST) at which users start their test sessions on Embibe. Medical (AIPMT) users have a defined spike around 10am and between 3pm to 5pm. Engineering (JEE) users, on the other hand, show gradually increasing session start times as the day progresses, which peaks around 4pm to 8pm. JEE students also consistently start more practice sessions between 5pm and 3am compared to AIPMT students. We are guessing doctors are more disciplined!
Our extensive instrumentation and measurement of user activity at a very granular level gives us the ability to infer latent preferences related to learning styles associated with individual users. For instance, certain students may learn, and thereafter perform on tests, better with the help of video explanations, compared to other students who prefer extensive textual descriptions, or still others who learn by working step-by-step through solved example problems. We can map users to well studied theoretical models of learning styles like the Dunn and Dunn Model (Dunn & Dunn 1989), or Gregorc’s Mind Styles Model (Gregorc 1982) to automatically tailor remedial courses of practice and help the user towards score improvement.
User cohorting
Cohorting is a classical clustering problem. Users are grouped based on their usage patterns with respect to product features as well as their performance patterns with respect to test, practice, and revision sessions. Each user is mapped to a high dimensional feature space of many thousands of attributes, which include static as well as temporal measures. Cohorting on temporal measures gives us the ability to cold start low activity and new users by assigning probable cohort trajectories to these users based on their initial activity. User cohorting is a core requirement for our higher level deep science features like micro-adaptive learning, automated feedback generation, and content recommendation.
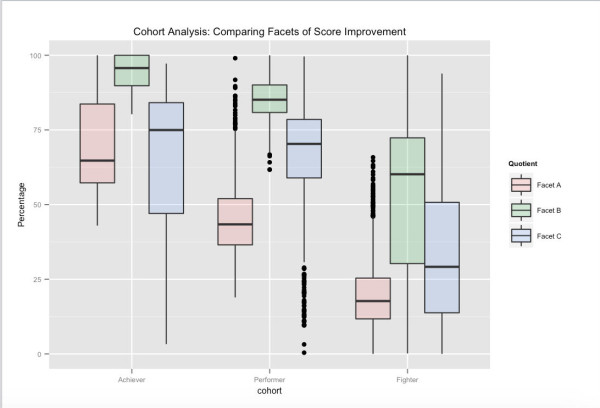
One possible view of user cohorts – tied to long term test performance. Based on their overall test scores, Achievers are the top percentile bracket of users on Embibe, Performers the next bracket, and Fighters the final bracket. The various facets shown, relate to different aspects of score improvement that we have clustered our feature space into. For instance, we can see that even though Facet_A varies significantly across cohorts, by targeting feedback to and affecting other learning facets, it is possible to push users into the next higher cohort.
Micro-adaptive learning
Bite-sized delivery of content and feedback is key to effectively learning online. Generally, users spend between 30 minutes to an hour online, practicing concepts and questions. Within this short time span, it is very important to maximise the impact of each time-bound session. Each session is an asset to the user to maximise learning, and this is best accomplished with the bite-sized strategy. Our micro-adaptive engine for practice sessions, takes a user’s profile and cohort attributes along with our knowledge tree of 11,000 (and growing!) interlinked concepts’ meta-attributes as input, and ensures that the question sequencing, hints provided, and just-in-time intelligent inline feedback adapts precisely to the user in order to improve her learning outcome on any bite-sized goal. Each bite-sized consumption of content or feedback will impact the user’s proficiency calibration against our extensive knowledge tree of concepts. Sparse matrix processing techniques, item response theory, and graph algorithms guide the micro adaptivity of learning.
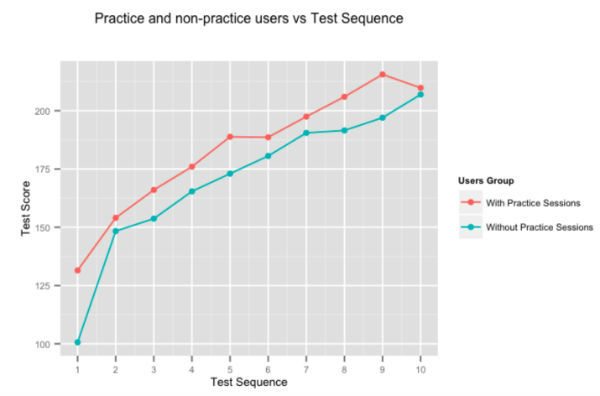
It is fairly obvious that practice makes one perfect, but we decided to run the numbers anyway. The figure above shows the average score improvement of users, for successive tests given by users who spend time on our adaptive practice sessions, and those who do not. Users who practice on Embibe consistently outscore those who do not by almost 10% test-on-test.
Feedback and recommendation system
Embibe’s feedback and recommendation system (on which we have filed patents already) is designed and built for one purpose – to maximise a user’s score improvement. We instrument and interpret thousands of signals about a user’s attempts during practice and test sessions, and transform these signals into a high-dimensional space of thousands of features for each user. Using statistical pattern mining on our massive user-attempt feature space, we have zeroed in on the ranked sets of parameters that positively drive up a user’s score. These parameters are machine-coded as highly targeted just-in-time capsules of score improvement feedback, and delivered to the user while she continues with her practice session. The feedback and recommendations expose weaknesses and strategies that she can adopt to maximise her score.
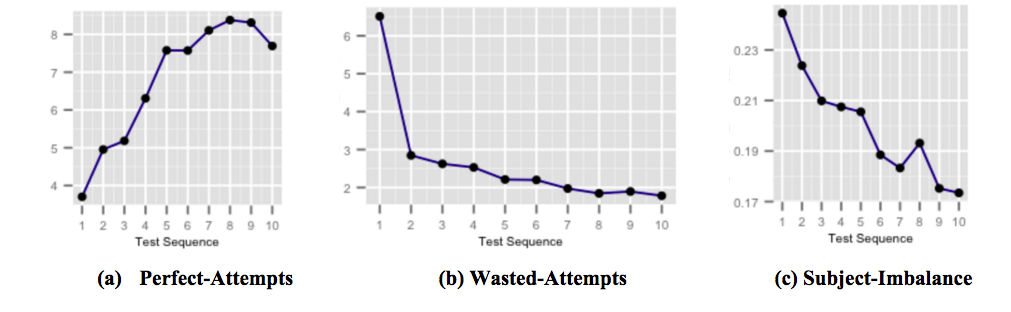
The figures above shows how our highly targeted just-in-time feedback capsules for score improvement affects student performance as the user is exposed to, and becomes aware of common test-taking pitfalls. Figure (a) shows the average number of perfect-attempts increasing over successive tests. Perfect-attempts are attempts which are correctly answered within some stipulated time. Figure (b) shows the average number of wasted-attempts decreasing over successive tests. Wasted-attempts are attempts which are incorrectly answered where the student had more time that could have been spent thinking about the question. And figure (c) shows the average subject-accuracy-imbalance decreasing over successive tests. Subject-accuracy-imbalance is defined as the difference between the highest and lowest accuracies among all the subjects in any test taken by a user. A higher subject-accuracy-imbalance implies that the user is less prepared for certain subjects compared to other subjects.
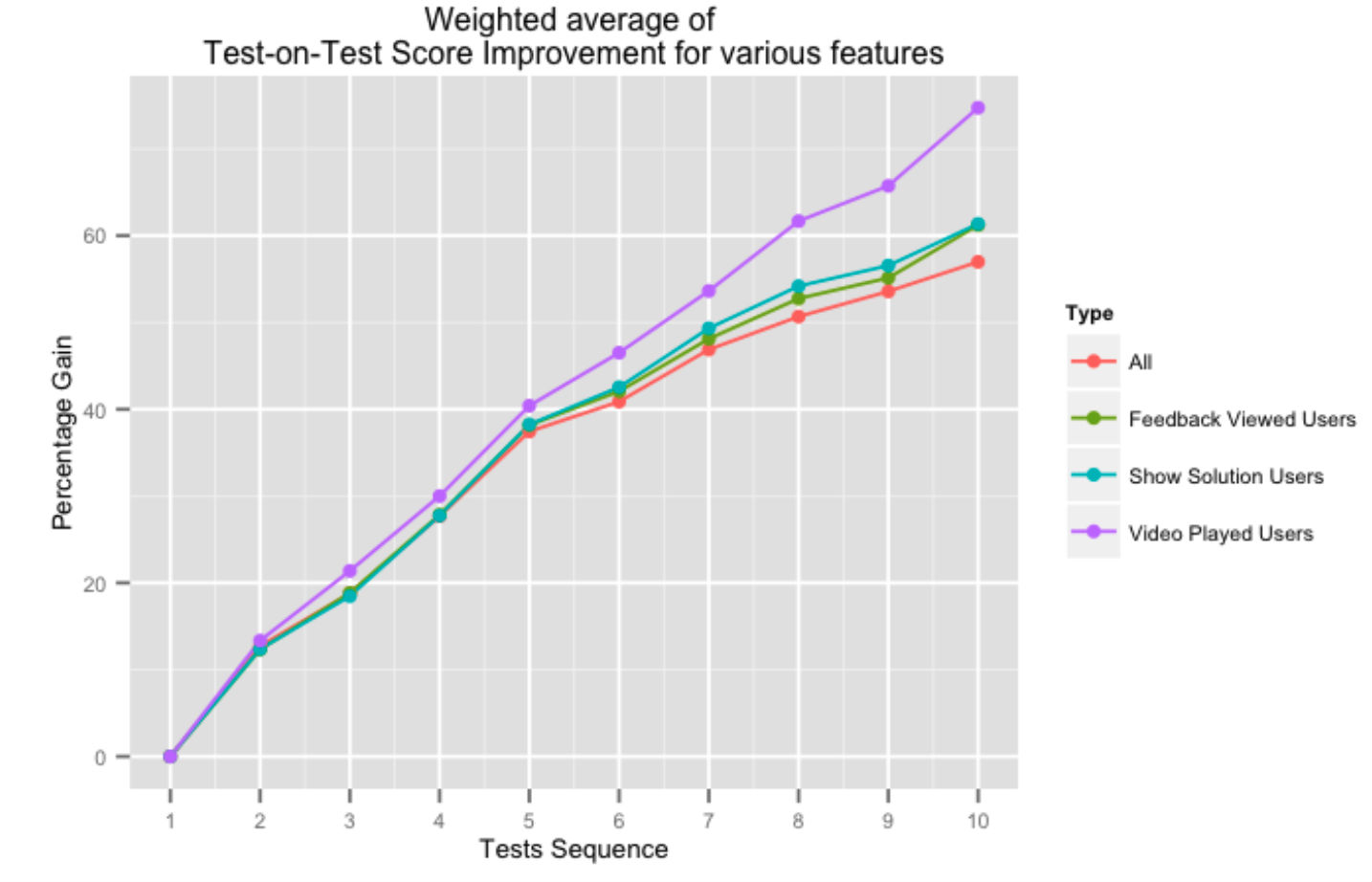
The figure above shows percentage gain in successive test-on-test scores for users who utilise various aspects of our feedback system. Taking help from our platform in the form of video solutions, or overall test feedback, positively impacts test-on-test scores, especially as the user completes more tests.
Estimating score improvement
To users who are preparing for exams of any kind, score improvement is the most important aspect of affecting learning outcomes. Our wealth of behavioural data gives us the ability to learn from past actions of users, by measuring how their behaviour during and after taking tests on Embibe affects score improvement. Data mining for statistical patterns in usage, activity, and behavioral features, among various cohorts of users, gives us science-backed proof of the effectiveness of our platform.
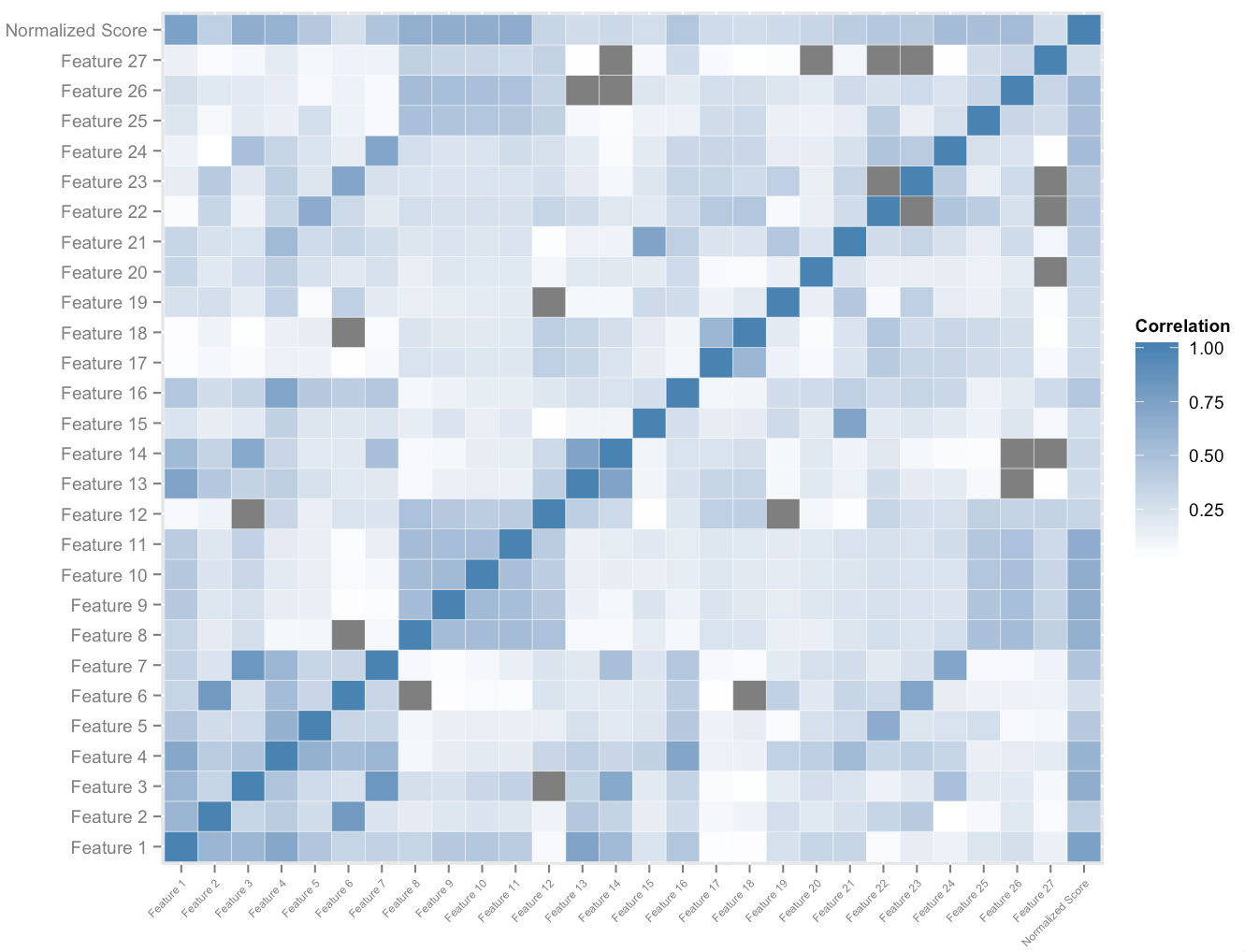
The figure above shows a subset of the feature space that we construct per user. Cross correlation analysis on the feature space and the overall normalized scores gives us an ordering on the relative feature importance. This, together with empirical dominance analysis, allows us to measure the quantum of impact of each feature on its contribution towards score improvement. An appropriately weighted combination of the velocities of the most important of these features enables us to quantitatively assign a measure of potential score improvement to each student, who adapts to her as she uses the platform.
These are exciting times for the field of education, especially in India and other developing countries. There is an urgent need to apply deep science, with a strong focus on using data and the insights it can provide, in order to take education and learning to the next level. Our content ingestion and delivery platforms are being constructed on solid scientific principles, and is helping users realise immense value on Embibe in the form of score improvement within constrained preparation time spans. Our micro-adaptive learning framework that utilises user-specific feedback and recommendations, tailored precisely to users, based on their cohort classifications as well as behavioural characteristics, allow users to have a fulfilling experience on Embibe. These are the first concrete steps towards solving the problem of positively impacting learning outcomes. This is personalised learning.
In this post, we touched on various sub-problems that need to be solved to move us along the road to affecting learning outcomes. In our next post, we will talk about how we measure and track various metrics at Embibe that are related to our users and their activity, in order for us to keep a finger on the pulse of our product, its growth, and its effectiveness as an online learning destination.
We are always on the look out for wicked smart folk to add to our ranks at the Data Science Lab. If you enjoy testing hypotheses, running regressions, factoring humongous matrices, laughing in the face of big data, firing off map-reduce jobs, building topic models over messy unstructured text, mining noisy data for statistical patterns, ingesting mountains of data from open data sources, arguing p-values, training neural networks and deep belief nets, switching between python and R, spinning up visualisations, and scripting shells, you will love it here!
Drop us a line with your resume at jobs.<id>@embibe.com, where:
<id> is the number formed with the first 8 non-zero digits of the value of the probability density function for the normal distribution, rounded to 19 digits of precision, and
mu is the 26th number in the Padovan sequence, and
sigma is the 17th number in the Fibonacci sequence starting at 1, and
x is the 1002th prime number 😉
Our team comprise of Keyur Faldu (Chief Data Scientist), Achint Thomas (Principal Data Scientist) and Chintan Donda (Data Scientist).
References
- Learning style inventory. Lawrence, KS: Price Systems.
- Gregorc A.F., (1982). Mind Styles Model: Theory, Principles, and Applications. Maynard, MA: Gabriel Systems.
Embibe has recently completed 3 years in the market as one of the foremost companies in education data analytics. Students have spent over 100K hours on the product in March 2016 alone with zero investment in paid marketing.