SUMMARY
Nikhil Kapur Discusses The State Of Deep Learning, First As A Student Developer And Now A VC




I spent one Saturday in a deep learning and TensorFlow workshop at the gigantic Level 3 office of Unilever Foundry and Padang.co. It was a fun day being immersed in the dev world again, and I enjoyed all the conversations with my tablemates, one of them running a family business and learning ML/deep learning as a hobby (he is a programming enthusiast) and the other from Marketing department of Zalora looking to apply some AI in her work.
We started off with setting up TensorFlow and Keras (an abstraction over TensorFlow) on our machines, and then started tinkering around with some of the common deep learning problems and examples such as using the MNIST dataset. Starting off with a simple little NLP model for text recognition, we dived into Convolutional Neural Networks, which turned out to be really fun to play around with.
We were using off the shelf pre-trained models, such as Inception V3 but were playing around with our own data sets and re-training the model to solve different problems such as “Is this a cat or a dog?” The goal of the class was to understand the basics of deep learning and experiment with parameters and features. If you are feeling jealous by now, then I suggest you go and play with playground.tensorflow.org, it was the easiest part of the workshop to get!
A huge shout out to Sam Witteveen and Martin Andrews for organising this. I recount here some of the perspectives I came off with, and where I see deep learning and AI in general heading, especially from a VC perspective.
Deep Learning From A Developer’s Perspective
To give a bit of background, I have had my fair amount of exposure to “AI.” In the second year of college, I interned in the Technology Consulting arm of Deloitte. Along with my friend Ujjwal Dasgupta, who later ended up doing a Masters in ML and is now at Google, I spent a couple of months churning out an improved ETL (Extract-Transform-Load) process on IBM Datastage, a Data Warehousing software. At the time, Ujjwal, who was always much more forward looking than I was, introduced me to data mining, and I started following Andrew Ng’s lectures and online courses.
Next summer, intrigued by the time I had already spent on the subject, I wanted to dive deeper into ML. I was lucky enough to get assigned to a project at Mozilla to improve Firefox performance using a machine learning-based compiler — Milespot GCC. Using this ML compiler, I was able to compile Mozilla Firefox’s code to result in around 10% improvement in program load time.
And then for my final thesis, there was no way I could let go of ML. I collaborated with DFKI, the German Institute for Artifical Intelligence to work on an extremely challenging project, using a simple webcam for eye tracking. The team at DFKI was using this for a particular application, Text 2.0. They were using a special HD camera to track your eyes and accordingly augment text with mega-cool features such as auto-scroll, auto-translate, popup dictionary, etc.
We decided to do the same with a simple webcam because no one in India had the money to buy that special HD camera. To be precise, we failed at it, only achieving about 70% accuracy in our tracking. But it was one of the most exciting projects I had worked on.


So why am I boring you with the details of this? Mostly to give you a bit of history to where AI was when I was grinding through my engineering. Even decades ago, deep learning and ML already existed, but it’s only in the last 10 years that the field has seen its coming of age. What exactly changed in the last few years?
Well, for one, Moore’s law took us to a point where the cost of storage and processing became minimal for somebody to implement ML at their home. You can now run pretty much all basic models on your own machine, and if you buy a good GPU (which is not that costly anymore), it can optimise your compute time by almost 10x to be able to run complex models.
Wired magazine has a great piece on this change.
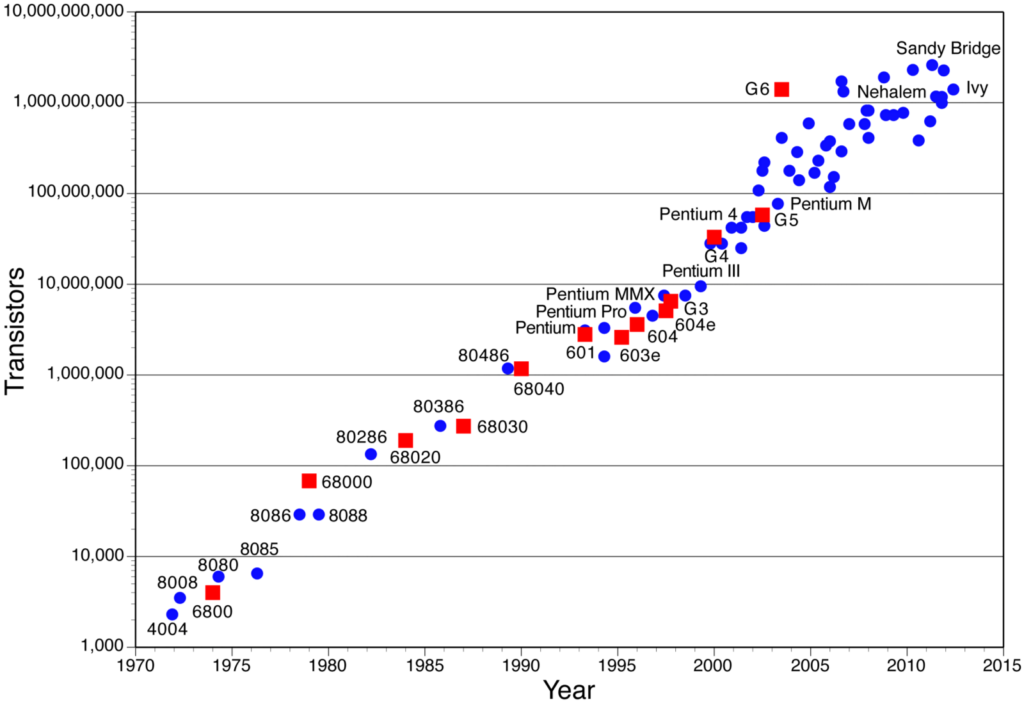
Number of Transistors in Chips over the year (note that Y-Axis is log scale!). Source: Assured-Systems
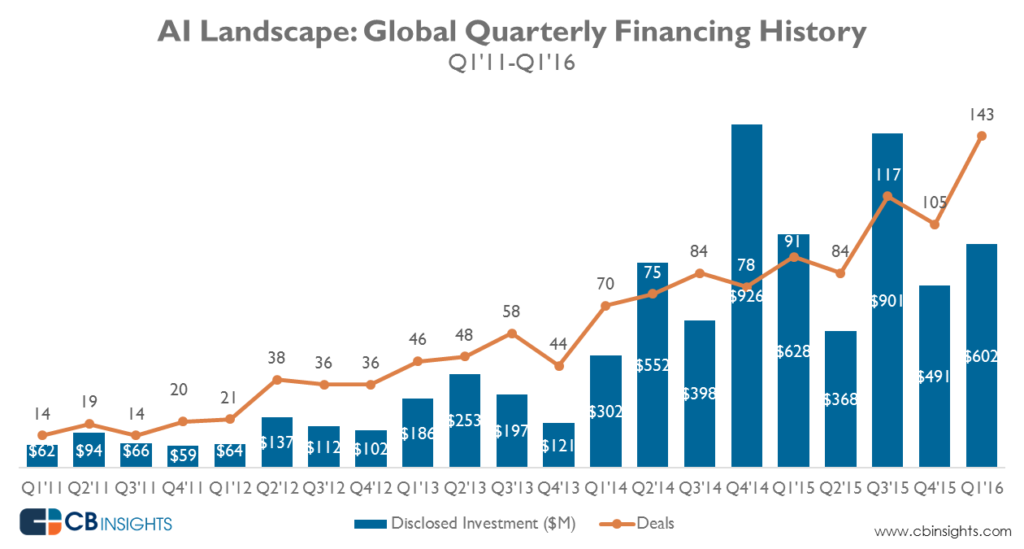
Another thing that has changed is that businesses have realised the need to automate. As a result of this, while M&A activity in the field has increased tremendously, VCs have been pouring in money into the field for the last 5 years.
Investor’s Outlook On Deep Learning
So where do we stand now and how should an investor or startup view this extreme buzz of AI? As I see it, there are four key aspects to an AI startup, all of which need to come together to form a strong company.
- Talent: It all starts here. While in a startup, the team is obviously the most important aspect, in an AI startup it is the real engine of the company. Access to strong data science and computer engineering talent to fine tune those pre-built models will be key for AI startups, and this is why US and Chinese startups are likely to have a lead on other geographies. Singapore does have a tiny sliver of data science talent and is likely to be a good place to set your AI company up. That said, the best talent will likely end up going to the tech giants either organically or inorganically. Google’s acquisition of DeepMind was exactly this, a play to acquire some of the best minds in Deep Learning.
- Data: If the team is the engine, then data is the gasoline in an AI startup. Without large amounts of clean and structured data, you are unlikely to be able to get any accuracy out of your trained system hampering the business applications. Due to the core dependency of a model’s prediction capabilities on the data fed in, large scale companies are likely to have a significant advantage over small scale start-ups on coming up with better and more accurate systems. This is a troubling thought and the only way to break the mould will be by generating and leveraging your own proprietary data. A system of records such as Salesforce is going to be immensely critical in this aspect.
- Model: All big tech giants are currently launching their own AI systems (dev platform, libraries, trained models) to create THE platform for tomorrow’s AI development. It is yet to be determined who’ll win the war but the need for creating models from scratch is sooner or later going to be over. Only for really complex systems would there be a need to start building your models from the basics, but in most cases, your data scientist will be able to reuse off-the-shelf models and retrain them using own data. How do you know that you have reached the best possible model though? Numerai, backed by Union Square Ventures, is tackling this problem in a very smart way, by crowdsourcing to ML experts and financially incentivising them to build better models.
- Business Problem: This is where things get interesting. Firstly, a user doesn’t care whether your systems are automated or not. AI systems are meant to optimise your own organisation and have a machine perform the task of a human, not to wow a user. Hence, solving a particular business problem is key to giving a good user experience and hence increase stickiness.
Secondly, most tech giants are going to restrict themselves to building a broad and generic platform. While tech companies such as Salesforce, Hubspot, etc are jumping on AI, theirs is likely going to be an acquisition route. Salesforce has already announced Einstein (though yet to follow through to its proclamations properly) and Hubspot is writing every week about AI on its blog. It only shows how interested they are in the field but also how difficult it is for them to target specific problems. This is where the gaps exist that a startup can exploit and our portfolio company Saleswhale is exactly going after this route.
In my eyes, if a startup solves through automation a very targeted problem which affects enough number of people using proprietary data that its systems collect on the way, it is likely to be a very lucrative business with strong barriers to entry. However, as far as I can see, this is unlikely to be a unicorn size opportunity in the region, not while the tech giants are still alive.
[This post by Nikhil Kapur first appeared on Medium and has been reproduced with permission.]