SUMMARY
Putting The Tech In EdTech




Consider the graph below. Think about how you grew up. The green line could be someone’s actual potential in life. The red line is what they are able to accomplish. Does this reflect your journey in your early years? Does this reflect your journey now? If it does, chances are you grew up in an emerging market. Like me.
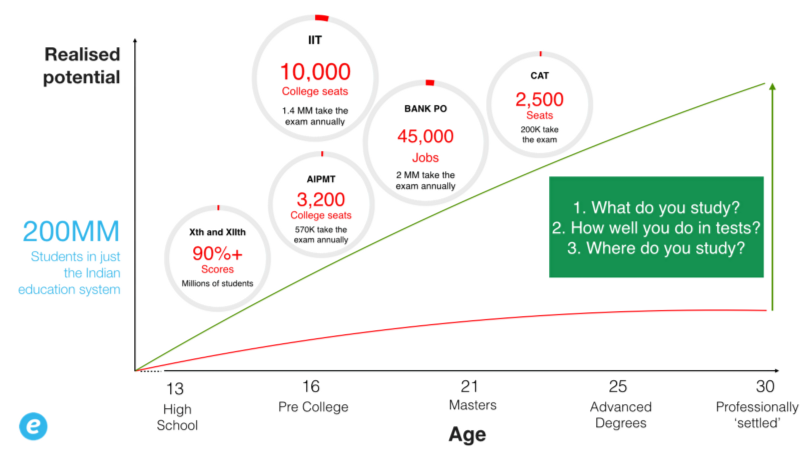
In countries like India with super low teacher:student ratios, the whole system relies on a series of scores to make an assessment of a person’s career potential. Access to better schools and colleges is almost always – solely contingent on achieving high scores. Better schools and colleges automatically ensure better employability options. In some cases like the public sector, these scores also determine access to jobs directly.
As such testing outcomes become proxies for learning outcomes where the whole system works to maximise test scores. The excitement of learning gets lost along the way.
The keys to better opportunity are linked to a better education.
The keys to a better education are simply linked to one number.
Let’s take an example. When it comes to choice of subjects, the largest number of Indian parents want their children to study engineering (23%). The JEE (the toughest exam in India focused on engineering) has a screening exam where 1.5 million students fight over 90 questions selected from around 8,000 concepts in 180 minutes to clear the cut-off. A similar dynamic is seen in medicine, law, management, accounting, etc.
An HSBC study shows that 91% of the Indian parents want their children to have at least an undergraduate degree or more and 88% want them to secure a masters or even higher degree. While China has the largest share of parents paying for additional tutoring (74%), India (71%) and Indonesia (71%) are not far behind. Hence, it’s not at all surprising that exams like the JEE attract an average private spend per student of roughly $1000 per year! (Put that in the context of a per capita GDP of $1500).

One would think that after this kind of spend and urgency, students would have access to a reasonably good level of teaching and personalised guidance. The whole premise of the private tutoring industry is rooted in the famous “Bloom’s 2 sigma problem” according to which “the average tutored student was above 98% of the students in the control class”. The thing is, in India today — most classrooms look like this — even in private tutoring models:

There is virtually zero access to personalised feedback or guidance for the average student. Teachers especially engineer the lectures in classrooms like these to be one-way interactions to ensure most classes end on time. To ensure that more ‘batches’ can be squeezed into the schedule in a day. There is also social censure against asking questions.
My favourite way of illustrating of what I call the ‘attention, ability & economics paradox’ is the following:
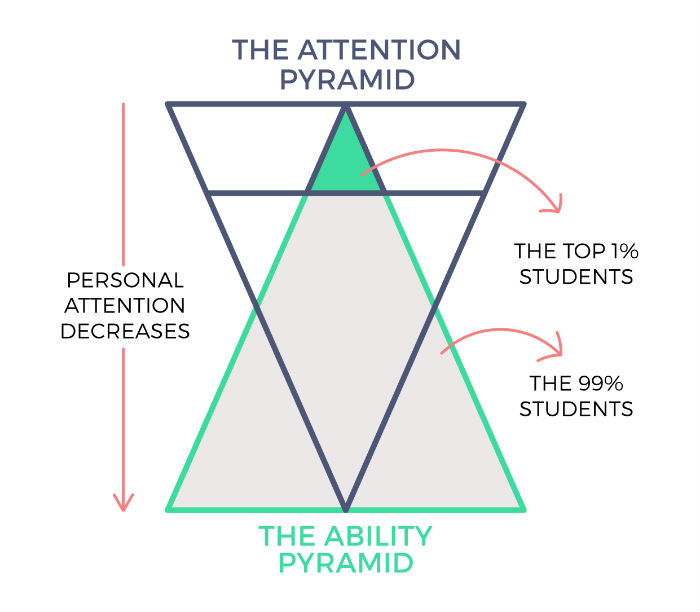
Ironically, if we superimpose the money paid by each student — that looks like this:
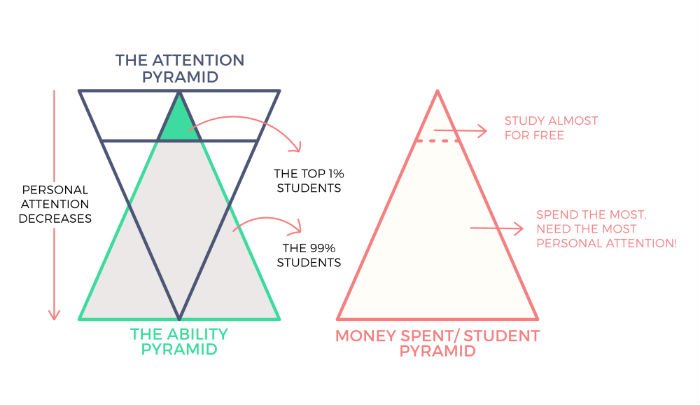
This is where things go further downhill. The students who need the most attention are the ones who get it the least. In fact, they start to mentally check out and are left to their own devices to solve for motivation, confidence and other behavioural issues. All this amidst stressful prep cycles. Deeper academic support only comes from peers or less trained substitute teachers in a one-to-many format.
The average student also ties in scores with self esteem. Because education is the one true meritocracy in the country — a huge percentage of students come from economically strained backgrounds. Parents spend beyond their means to help their children ‘score higher’. Working crazy hours, they try to vindicate their parents’ spend and stress out completely. This is made worse by the implication of losing even a single mark — in the JEE for example, 95% of students score below 30% and each mark is worth 10,000 positions on the merit list. Sometimes, this kind of pressure results in heart-wrenching tragedies.
This is how the future leaders of the most densely populated countries in the world are pursuing education today. Judged by a single number, with multi billion dollar education markets thriving despite the near-anonymity of the student. With 15 million new babies born each year, how will things get better?
Fortunately, as I have realised through embibe’s journey — deep tech and data science is the answer. But first, lets peel a few layers of the onion.
Learning is a Continuum, but Education Delivery is Not
Intuitively, it’s easy to understand that the learning process is a continuum, with every layer of concepts and every grade level building on the knowledge from previous levels.



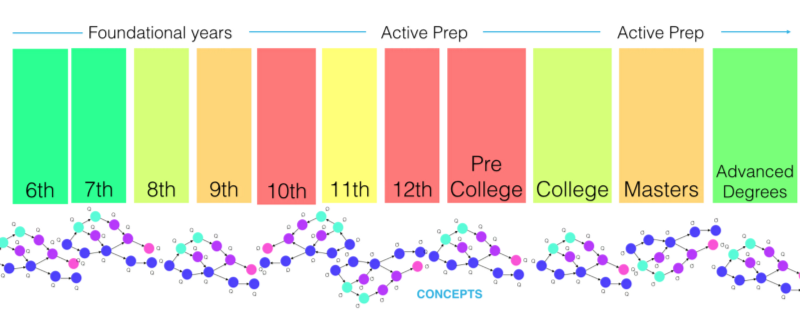
GPA or percentage based annual school assessments give way to the standardised test scores. Post the 10th grade, the average concepts tested per question increase from 1 to 3. Rote learning or last-minute cramming become ineffective. The pressure intensifies with pre-college test prep — be it the SATs in the US or the JEE in India, the Gaokao in China etc. The fun continues post college, with exams that further decide employment outcomes, often testing understanding of concepts from many years prior.
As a result, vast industries exist — solving for specific tests and grades in small pockets across the board. Some of these (just for India) are illustrated below.
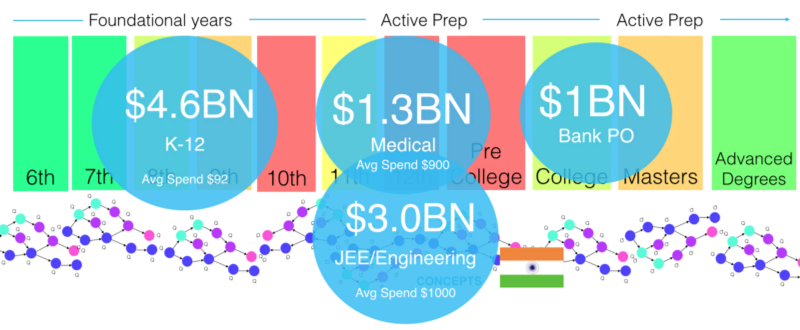
My problem is the inefficiency with which this industry is structured. This whole industry is designed to suit the convenience of education delivery, not maximise outcomes for the student.
With this segmented approach to education delivery, there is no continuity of learning data or information as the student goes from age 5 to 30 years.
Our education system is structurally designed to keep losing and recreating student data and context — a fundamentally inefficient way of solving for skilling and also a massive wastage of resources.
In many of these pockets, I have heard teachers say: ‘If only you had studied harder in the 9th, your concepts would have been clearer in the 11th.’Quantitative aptitude for the public sector Bank Probationary Officer Exam is based on high school math. Pass marks average at 35% at every grade— you could pretty much ignore critical building blocks for future milestones and still pass the class.
Without a granular and continuous view of the conceptual graph that connects learning across grades and tests, even the best adaptive learning solutions can just solve for “local maxima” to the extent that their limited content permits them. This graph can also help an education business meaningfully address the age-old problem of churn .
There is nothing available to nudge the student continuously on how — what she studies today connects with what lies ahead.
But then, tech can change all that!
I studied a lot but I don’t know what happened!
Beyond the problem of continuity discussed above, ed tech in emerging markets has to solve for a second, glaring mismatch. The difference between ability and actual scores.
We conducted a small survey recently of the top reasons why students lose marks. The top 5 results had little to do with learning:
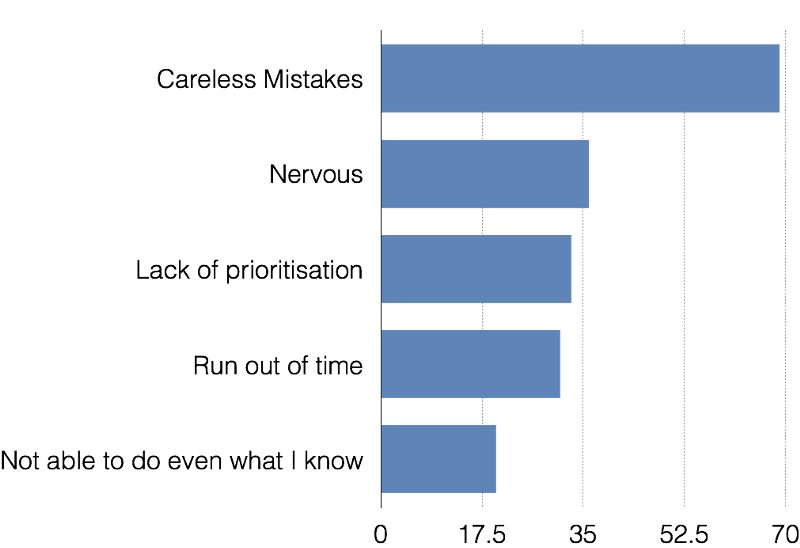
This means that even after learning — things like test taking skills and behaviour/confidence become the two biggest levers to realise scores. The question is: how does one control or influence these? For the average student. For the masses.
The big question — Zero to One
We took a step back to look at large scale consumer tech businesses. The common theme was very interesting. Each of them was committed to solving one problem correctly, in a 10X differentiated manner and at scale. For us — the analog for ed tech was very clear – personalisation driven learning outcomes at scale.

Three years ago — embibe started down this journey. Intrigued by Avichal Garg’s post — ‘Why education tech startups do not succeed’ — we were determined to build a quality product that can actually make a dent in student performance in emerging markets. At the same time, ensuring that a short supply of inadequately compensated teachers don’t have to take on additional workload.
Turns out it is possible to move up both academic proficiency and test taking technique as well as positive behaviours by giving students detailed analysis on the parameters that make up these factors.
Our research has distilled over 5 billion insights in student test taking to 27 parameters. These parameters can predict and impact scores to the tune of 93%.
This is the result of 3+ years of talking to hundreds of teachers, observing thousands of tests in person, analysing hundreds of thousands of hours of engagement on the platform across 300 cities.
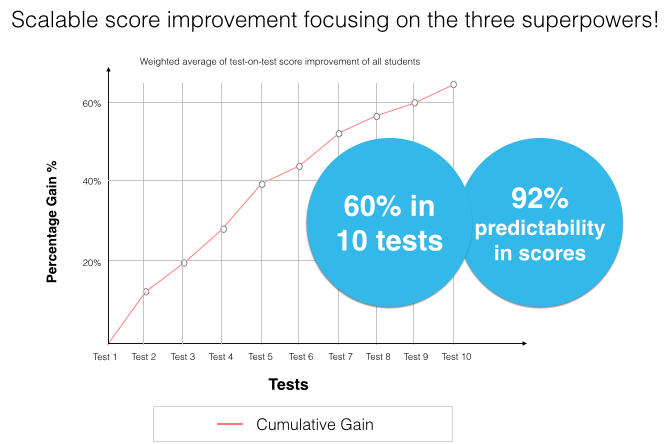
The most awesome thing is that these parameters are generic and can be abstracted to any curriculum. Our ‘education genome’ — is an incredibly dense graph concepts from science and maths . It identifies byte sized gaps in student learning and provides byte sized learning to remedy them. This graph makes learning a true continuum over 5 years of education and is the backbone of our adaptive algorithm.

Our focus on behavioural and test taking parameters also accelerates score improvement vs. focus on learning alone. Short term improvement is also a great motivator to move student morale up. All leading to deeper engagement for an impatient market.
[vimeo 152049489 w=500 h=281]
Further, investments in the platform have ensured the ability to rapidly scale to support any curriculum from any country. We want to create true, meaningful convergence between the teacher, student data and personalised content in the future.
Emerging markets are still largely seeing edtech businesses focused on building content online. Embibe instead is building the context for the student to use any content more effectively. The possibilities that can arise from deep application of tech and data science in education are 10X more rewarding when the stakes are so high.
We are thrilled to announce the filing of the first patent of its kind in personalised learning designed for students in emerging markets. This is authored by embibe’s Chief Data Scientist, Keyur Faldu; Principal Data Scientist, Achint Thomas and me. Stay tuned for details on embibe’s exciting Data Science Lab and much more.